Aug 25, 2020
This article is about a fairly niche topic you may encounter when implementing a deflate compressor or decompressor. I assume you are familiar with huffman coding, but I try to explain the relevant concepts used in deflate.
Deflate's dynamically encoded blocks (block type 2) use custom huffman codes generated on the fly for each block. In order for these codes to then be interpreted, the compressor must somehow transmit the custom codes to the decompressor.
Naive huffman coding implementations may simply serialize the full code, writing information such as the bit length and code for each symbol. However this information quickly takes up large amounts of space, and can result in a net negative for compression.
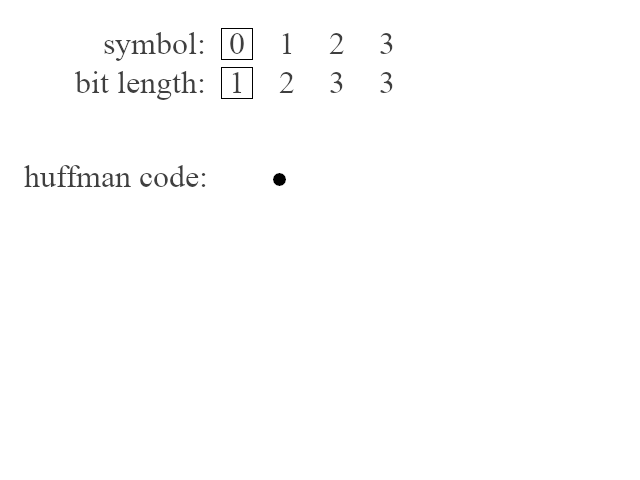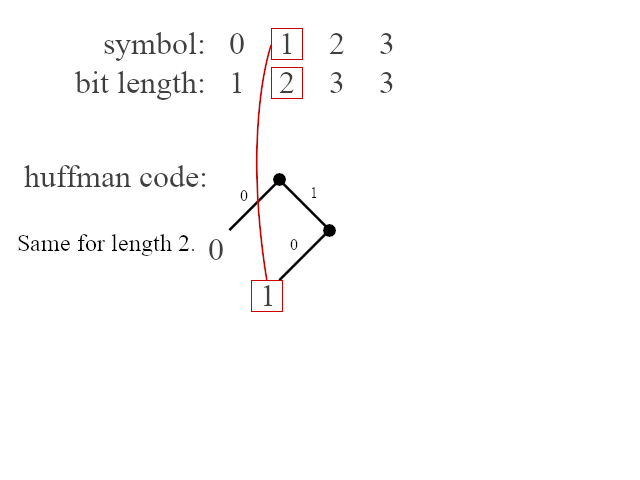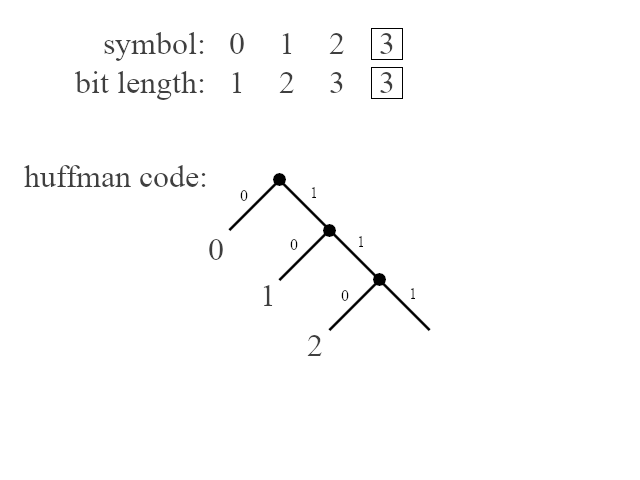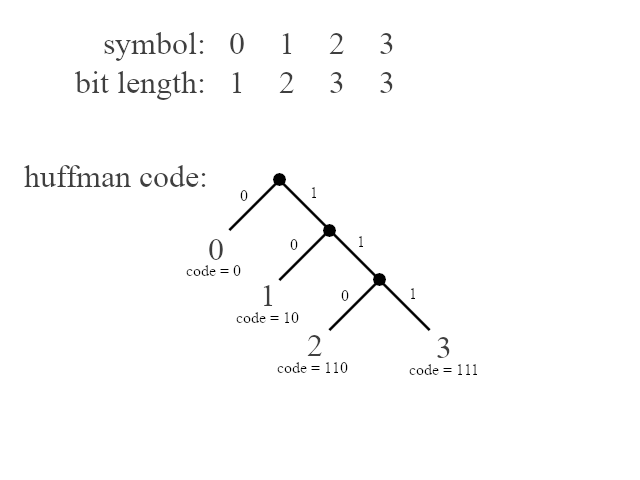
Deflate is more precise. The compressor transmits only a set of bit lengths, one for each symbol in an alphabet, in order. The decompressor then recomputes the codes in a pre-coordinated way (this technique is known as canonical huffman coding). This is done using principles illustrated by the following animation:
There are some rules that define an optimal relationship between the lengths of a given code. They are essentially the same properties laid out by David A. Huffman in the famous paper "A Method for the Construction of Minimum Redundancy Codes." For example, no code should go unused. If there is an unused code of length n, and a symbol is assigned to a code of length n + 1, then the symbol could simply be reassigned to the code of length n, and a more optimal code would be produced.
zlib refers to codes with unused bit patterns like this as "incomplete." Although it is possible to produce an incomplete but still correct code, it is considered that programs conforming directly to the deflate spec would follow the code assignment in the RFC section 3.2.2, and so they would produce a proper huffman code length set. The reasoning given by Mark Adler on StackOverflow for throwing an error on incomplete sets is in order to rapidly detect and reject random or corrupted data:
The bottom line is, no, you will not be able to use an incomplete code in a dynamic header (except the special case) and expect zlib or any compliant deflate decoder to be able to decode it.
As for why this strictness is useful, constraints on dynamic headers permit rapid detection of non-deflate streams or corrupted deflate streams. Similarly, a dynamic header with no end code is not permitted by zlib, so as to avoid the case of a bogus dynamic header permitting any following random bits to be decodable forever, never detecting an error. The unused fixed codes also help in this regard, since eventually they trigger an error in random input.
It is also possible for a code to list too many symbols on the same bit length. A simple example would be to provide a code with 3 symbols with a bit length of 1. The first symbol could be assigned a code of 0, and the second symbol a code of 1, but the third symbol has no bit pattern of length 1 available to it.
zlib refers to these codes as "over-subscribed," and returns an error for these codes as well, seeing as there is no reasonable way to interpret such a code.
The following code snippet from inftrees.c in zlib detects both incomplete and over-subscribed codes:
/* check for an over-subscribed or incomplete set of lengths */ left = 1; for (len = 1; len <= MAXBITS; len++) { left <<= 1; left -= count[len]; if (left < 0) return -1; /* over-subscribed */ } if (left > 0 && (type == CODES || max != 1)) return -1; /* incomplete set */
If you trigger either of these errors, you've likely made a mistake in calculating your bit lengths, or in writing them out to the file. In my case, I made an off-by-one error when calculating hlen, and so I wrote out all code lengths except the last, resulting in an incomplete code. This is a point in favor of returning an error on incomplete codes!
To bring this article to a close, I would like to take this opportunity to say Mark Adler is a goated baller legend-man and without his consistent presence on StackOverflow, implementing deflate would have taken me much longer.
Copyright Brendan Dougherty 2020.